



How does MySQL achieve master-slave synchronization?
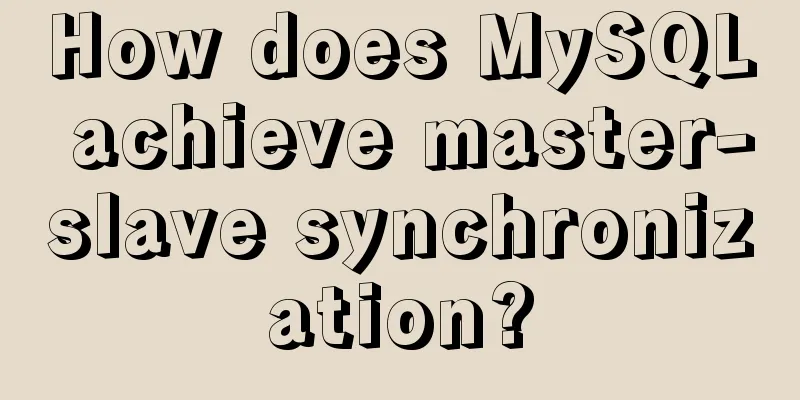
|
Master-slave synchronization, also called master-slave replication, is a high-availability solution provided by MySQL that ensures master-slave data consistency. In a production environment, there will be many uncontrollable factors, such as database service failure. To ensure high availability of the application, the database must also be highly available. Therefore, in production environments, master-slave synchronization is used. When the application is small in scale, one master and one backup are generally used. In addition to the ability to quickly switch to the standby database when the database service fails and avoid application unavailability, the use of master-slave synchronization has the following benefits: Improve the read concurrency of the database. Most applications require more reads than writes. Use a master-slave synchronization solution. When the scale of use increases, you can expand the slave database to improve the read capability. Backup, master-slave synchronization can obtain a real-time and complete backup database. Quick recovery: When an error occurs in the primary database (such as accidental deletion of a table), data can be quickly restored through the standby database. For large-scale applications with low tolerance for data recovery speed, a backup database can be configured with a data snapshot half an hour apart from the primary database. When a table is accidentally deleted from the primary database, it can be quickly restored through the backup database and binlog, with a maximum wait of half an hour. Now that we have discussed what master-slave synchronization is and its benefits, let us now understand how master-slave synchronization is achieved. Implementation principle of master-slave synchronizationLet's first understand the principle of master-slave synchronization. The following uses an update statement to introduce how the master and slave databases are synchronized.
The figure above is a complete flow chart of an update statement executed on node A and then synchronized to node B. The specific steps are:
The working principle of master-slave synchronization is actually a full backup plus the restoration of the binary log backup. The difference is that the restore operation of this binary log is basically real-time. The standby database uses two threads to achieve synchronization:
From the above process, we can see that the key to master-slave synchronization is binlog Two common active/standby switching processes MS structureIn the MS structure, there are two nodes, one serving as the primary database and the other as the backup database. The two nodes are not allowed to exchange roles.
In state 1, the client's reads and writes directly access node A, and node B is the backup database of A. It just synchronizes all updates of A and executes them locally. This keeps the data on nodes B and A the same. When switching is required, switch to state 2. At this time, the client reads and writes to node B, and node A is the backup database of B. Double M structureDual M structure, two nodes, one as the primary database and one as the backup database, allowing the two nodes to exchange roles.
Comparing with the previous MS structure diagram, we can find that the only difference between the dual M structure and the MS structure is that there is one more line, that is, nodes A and B are always in a master-slave relationship with each other. This way, there is no need to modify the master-slave relationship during switching. The Circular Copy Problem of Double M StructureIn actual production use, the double M structure is used in most cases. However, the double M structure still has a problem that needs to be solved. When the business logic is updated on node A, a binlog is generated and synchronized to node B. After node B is synchronized, binlog is also generated. (log_slave_updates is set to on, indicating that the standby database will also generate binlogs). When node A is also the backup database of node B, the binlog of node B will also be sent to node A, causing circular replication. Solution:
The process after solution:
The above is the details of how MySQL achieves master-slave synchronization. For more information about MySQL master-slave synchronization, please pay attention to other related articles on 123WORDPRESS.COM! You may also be interested in:
|
>>: Detailed steps for debugging VUE projects in IDEA









Recommend
A brief analysis of the usage of HTML float
Some usage of float Left suspension: float:left; ...
Sublime / vscode quick implementation of generating HTML code
Table of contents Basic HTML structure Generate s...
Analysis of MySQL duplicate index and redundant index examples
This article uses examples to describe MySQL dupl...
Two ways to understand CSS priority
Method 1: Adding values Let's go to MDN to se...
MySQL 5.7.25 installation and configuration method graphic tutorial
There are two types of MySQL installation files, ...
Some common mistakes with MySQL null
According to null-values, the value of null in My...
Key knowledge summary of Vue development guide
Table of contents Overview 0. JavaScript and Web ...
Uniapp realizes sliding scoring effect
This article shares the specific code of uniapp t...
MySQL 8.0.18 stable version released! Hash Join is here as expected
MySQL 8.0.18 stable version (GA) was officially r...
Basic understanding and use of HTML select option
Detailed explanation of HTML (select option) in ja...
Summary of the use of html meta tags (recommended)
Meta tag function The META tag is a key tag in th...
MySQL grouping queries and aggregate functions
Overview I believe we often encounter such scenar...
Detailed explanation of Svn one-click installation shell script under linxu
#!/bin/bash #Download SVN yum -y install subversi...
JS realizes the scrolling effect of announcement online
This article shares the specific code of JS to ac...
How to install Oracle_11g using Docker
Install Oracle_11g with Docker 1. Pull the oracle...